Scouting the flow of data for the future High Luminosity LHC
How to manage large amounts of data without losing any interesting ones? The selection of data concerning particle collisions in the LHC is critical since it will determine all the resulting analyses. This is the decisive work of a novel scouting system located at the beginning of the data chain.

The CERN accelerator complex propels charged particles close to the speed of light. After being injected into the Large Hardon Collider (LHC), the most powerful accelerator in the world, these are collided at different points corresponding to the laboratory's multiple experiments. One of the largest of these is the Compact Muon Solenoid (CMS), a general-purpose detector which has a broad physics programme ranging from studying the Standard Model (including the Higgs boson) to searching for extra dimensions and particles that could make up dark matter. Two beams of particles are sent in opposite directions inside the LHC, guided by magnetic fields about 100,000 times stronger than the magnetic field of the Earth, circle it more than 11,000 times per second, and then are aligned to create some 40,000 million collisions per second at the heart of detectors such as the CMS.
These gigantic numbers represent a real challenge given the quantity of data produced. The management of the data flow must therefore be meticulously conceptualised in order to efficiently sort it to keep only the “events” with distinguishing characteristics, such as interactions or collisions of particles recorded in particle detectors. Concretely, this process of selecting interesting data to send to the data centre for analysis consists of different levels of triggers which will automatically activate according to criteria that must be judiciously defined, and will capture the event to translate it into data. The CMS has a two-stage trigger system selecting the most interesting collision events for read-out and analysis. It is to meet this challenge that the CMS teams regularly organise hackathons at IdeaSquare aimed at exploring the design possibilities of the data flow, and the technologies that can be used for triggers.
As with every filter system, potentially interesting data has to be discarded, for instance, because its signature is identical to that of the very large background. To mitigate this issue the novel Level-1 (L1) scouting system has been under development since 2018. While the traditional data-taking method is to record those events selected by the trigger at the full detector resolution, scouting takes an alternative path: in this scheme, the data that was reconstructed quite coarsely within the trigger to come to a readout decision is used for the actual analysis. By doing so, the entire data seen by the detector can be read out and analysed. The first DARTS hackathon was held to work on the data acquisition, run control, and trigger interfaces to the scouting system.
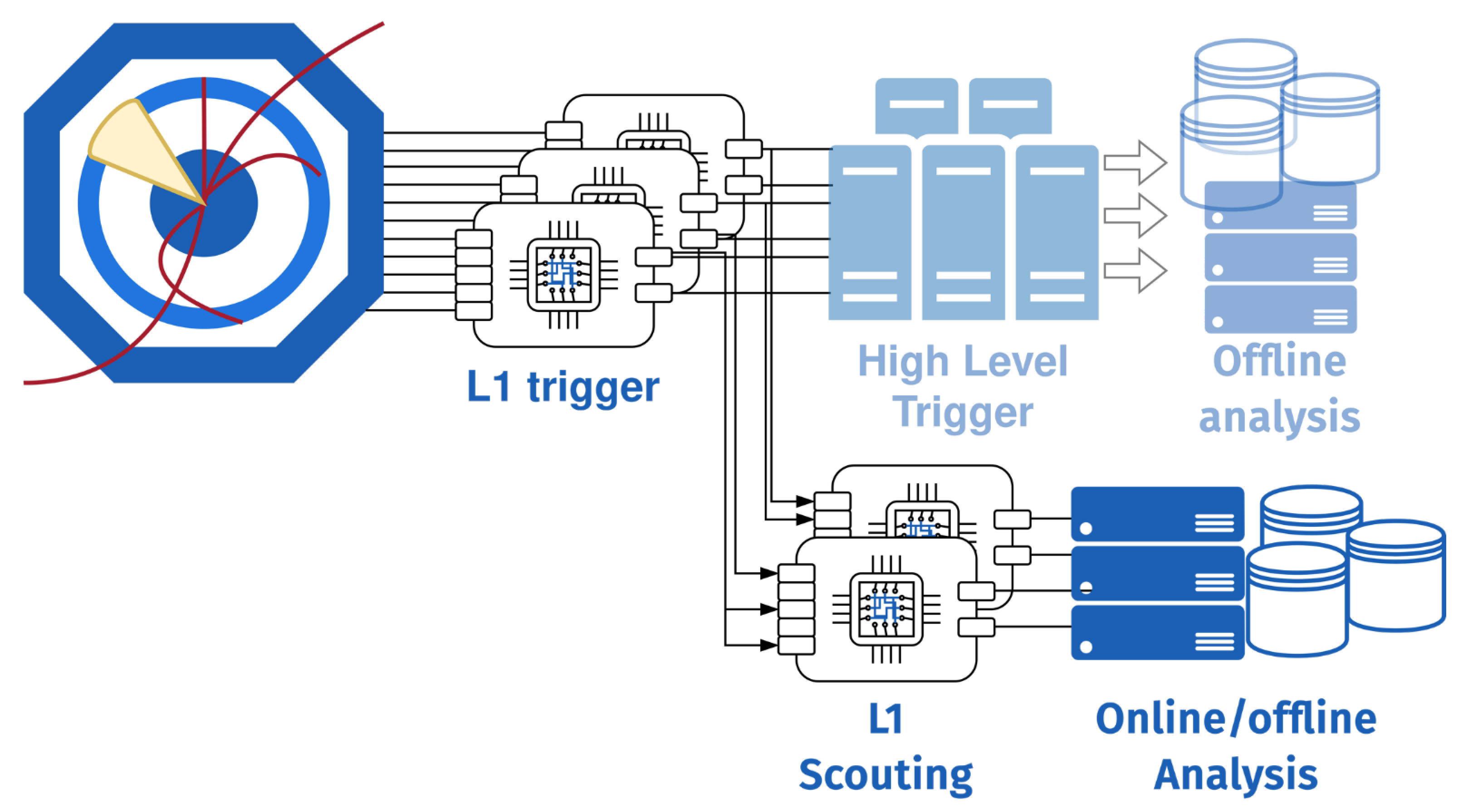
The aim of the DARTS hackathon with the CMS teams at IdeaSquare was to work on scouting as it currently exists, but also to foresee the future of the system for the High Luminosity (HiLumi) upgrade of the LHC. They work on a demonstrator integrated at Point 5 (CMS) that is used to take LHC data most of the time but is also a test bed for HiLumi, allowing them to explore both the hardware system and the design of the algorithm and software. The participants were divided into specialised groups for the upgrade of the trigger for HiLumi, for the adaptation of the readout boards, for the preparation for dealing with real-time data integrated into the Data Quality Monitoring, for the tests on the computing architecture, and of course for the Function Manager of CMS that controls all sub-system. In addition, a neural network-based re-calibration and fake identification engine has been developed, as well as the first implementation of a real-time analysis within the scouting demonstrator system.
All this helps to flesh out the plans and development progress towards the continued expansion of the scouting system for the High Luminosity LHC. This crucial work lays the groundwork for the future of the LHC and allows better to channel the influx of data from the HiLumi upgrade into fundamental new discoveries for physics and for the understanding of our universe.